上回介紹了聯邦式學習,這次來介紹一個相關的主題,去年神經信息處理大會(Neural Information Processing Systems,NuerIPS) 的會議上出現一篇論文:Data Leakage from Gradients [1],後續還有一篇相關的論文:Improved Deep Leakage from Gradients [2],今天來介紹一下這論文在討論什麼。
假設有 $K$ 個獨立的資料中心,每個資料中心都有各自的資料庫 $D_k = {(x_n^{(k)}, y_n^{(k)})}{n=1}^{N_k}$,現在考慮一個影像辨別的問題,所以 $D_k \in {0, 1, \ldots 255}^{m \times p \times 3} \times {1, 2, \ldots, \text{C}}$,也就是一張 $m \times p$ 大小的彩色圖像,每張圖像會有一種類別,總共有 $\text{C}$ 個類別,如我們架了一個深度學習網路模型 $f\theta: \mathbb{R}^{m \times p \times 3} \rightarrow \mathbb{R}^\text{C}$,其中 $\theta$ 是要訓練的參數,每次只訓練一筆資料,損失函數為 $\lambda (f_\theta (x_i^{(k)}), y_i^{(k)})$,另外使用聯邦式學習來訓練模型,所以會傳輸 $\nabla \left. \lambda (\theta) \right|_{D_k}$ 到伺服器。
假設現在駭客可以竊取到傳輸的 $\nabla \left. \lambda (\theta) \right|{D_k}$,並且知道模型架構 $f$ 及當下的參數 $\theta$,則我們可以利用演算法推回當次訓練的 $(x_i, y_i)$,如果是批量訓練,則可以推回 ${x_i, y_i}{i=b_i}^{b_i+\text{batch-size}}$,也就是那個批量的資料,此演算法顯示了聯邦學習具有資料洩漏的風險。
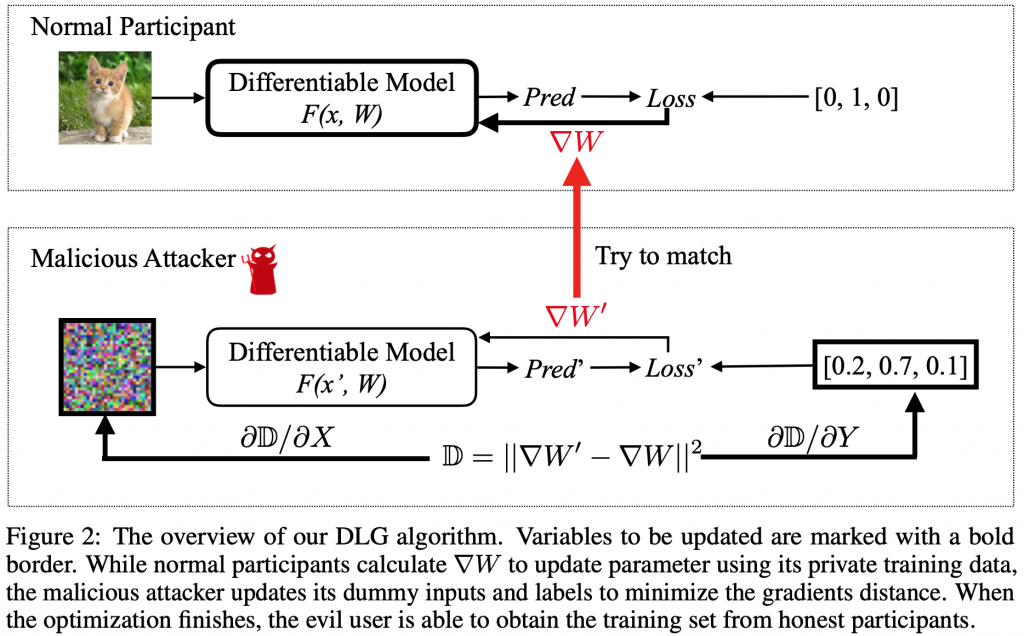
(圖片取自:[1])

(圖片取自:[1])
[1]:Zhu, L., Liu, Z., & Han, S. (2019). Deep leakage from gradients. In Advances in Neural Information Processing Systems (pp. 14774-14784).
[2]:Zhao, B., Mopuri, K. R., & Bilen, H. (2020). iDLG: Improved Deep Leakage from Gradients. arXiv preprint arXiv:2001.02610.

